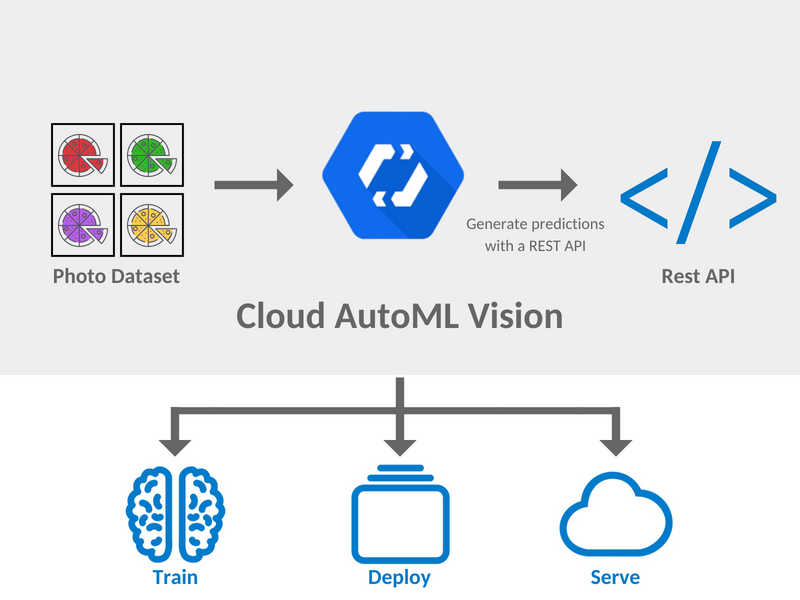
Det er to ting vi må få på plass før vi fortsetter – forskjellen mellom Google Cloud Vision API og AutoML Vision. Disse går litt hånd i hånd, og kan være vanskelig å skille for det utrente øye. Vision API er Google sin ferdigtrente bildegjenkjenner, som har vært tilgjengelig en liten stund. Det er veldig rett frem å ta i bruk. Eksempelvis kan du gå inn her, scrolle bittelitt ned på siden, og dra et vilkårlig bilde fra PC’en din inn i den stiplede ruten. Du ender da opp med et lignende resultat, basert på hvilket bilde du valgte.

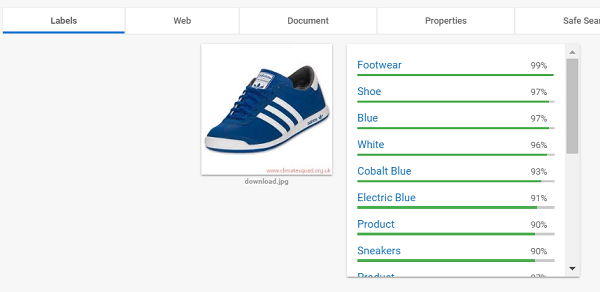
Herlig, du har nå brukt Google sitt Vision API. Hvis dette ga deg det du var ute etter, så trenger du ikke ta steget videre til AutoML. Men la oss si at disse kategoriene “Footwear, Shoe, Blue” osv. ikke var det du ville ha som svar. Det er i dette tilfellet AutoML kommer for å redde dagen. Du kan nemlig legge inn egne definisjoner for bilder, og trene opp AutoML Vision til å kjenne igjen lignende bilder. Når jobben er gjort og du har satt opp AutoML Vision, vil det kunne brukes på akkurat samme måte som Cloud Vision, men du har selv definert de ulike kategoriene og gruppene som et bilde skal bli plassert i.
La oss fyre opp et eksempel i Google Cloud og se om vi kan få noe vettugt ut av det. Først trenger vi et Google Cloud-prosjekt med et passende navn.
Videre må vi forsikre oss om at prosjektet har det som trengs. Vi må ordne med en “storage bucket” som skal holde på alle bildene våre, og en tilhørende csv-fil som beskriver bildene. Vi må også skru på alle API’ene som AutoML har behov for. Dette gjør vi ved å følge oppskriften som Google selv har skrevet her. Her forklarer de hvordan vi skal skru på “billing” for prosjektet, sette opp nødvendige API’er, og ordne med en «storage bucket». Videre forklarer de hvordan vi kan kopiere bilder og filer fra deres eksempel, men istedenfor å kopiere deres ferdige datasett og csv-fil, lager vi våre egne. De har jo tross alt ikke løst vårt problem med sine bilder og kategorier!
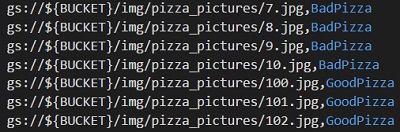
I vår “storage bucket” lager vi to mapper. Den ene kaller vi “img”, og fyller med bilder av pizza. I den andre mappen legger vi inn en csv-fil, og på lik linje kaller vi bare mappen for “csv”. Pizzabildene består av et utvalg pizzaer både med og uten ananas, og csv-filen beskriver lokasjonen til hvert enkelt bilde, med en tilhørende kategori.
Vår csv-fil er vist under, og i dette tilfellet heter bildene våre bare “1.jpg, 2.jpg” osv., og de har fått tildelt tittelen “BadPizza” eller “GoodPizza”. Der det står {BUCKET} fyller man inn navnet på “storage bucketen” man bruker.
Da er alt på plass. Vi har satt opp prosjektet vårt med lagringskapasitet som holder på bilder, og en csv med tilhørende kategorier. Vi har skrudd på alle nødvendige API’er, og er klare for å sette i gang. Kjør AutoML!
På Google Cloud-dashboardet vårt kan vi nå åpne navigasjonsmenyen øverst til venstre, og scrolle helt ned til vi finner “Vision” under “Artificial Intelligence”.

Dette tar oss inn i et oppsett hvor vi velger hvilket prosjekt vi ønsker å bruke AutoML på. Vi velger såklart det prosjektet som vi alt har gjort i stand. Videre kan vi enten velge å laste opp bilder, eller å la en csv-fil fortelle AutoML hvor bildene ligger og hvordan de er kategorisert. Siden vi er bittelitt tekniske, og har en slik csv-fil, velger vi sistnevnte. Men her kan man også løse problemet med en god gammeldags “last opp fil”-knapp.
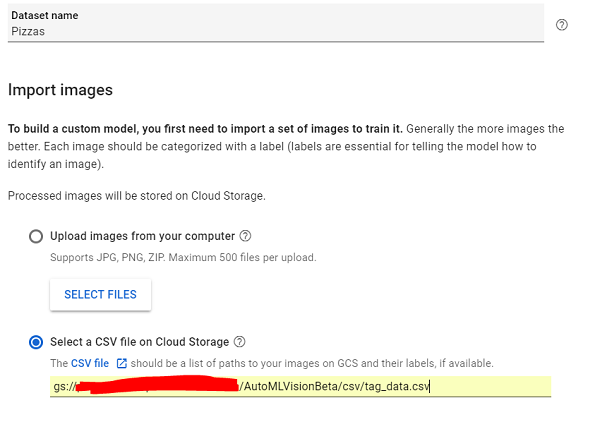
Etter litt tenketid blir du tatt inn i AutoML Vision sitt nye dashboard hvor man har oversikt over alle bildene sine, samt hvilke av bildene som har fått tildelt en kategori, og hvilke som ikke har det. I vårt tilfellet har vi allerede kategorisert alle bildene, men hvis man eksempelvis har en mappe med flere tusen bilder kan man kategorisere et titalls stykker, og la AutoML gjøre resten av jobben.
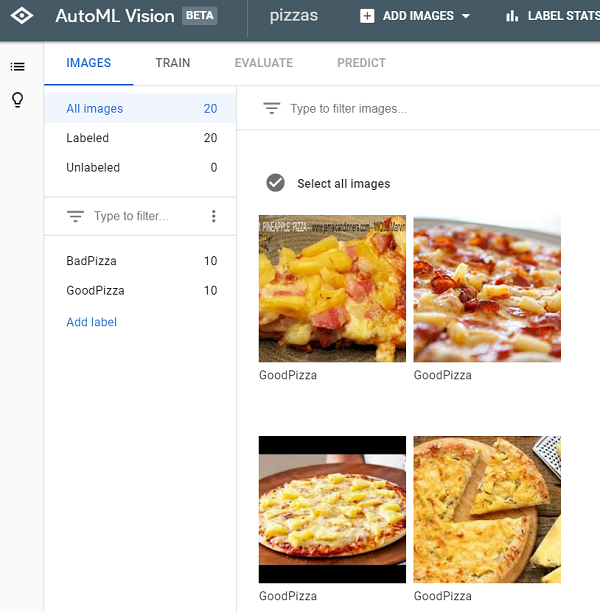
Alt er nå klart til at vi kan trene opp ML-modellen vår til å gjenkjenne hva en god og en dårlig pizza er!
Med våre ti bilder per kategori er vi akkurat på minimumskravet til hva Google krever for å trene opp en modell. Med færre bilder enn det, vil man antakeligvis få et altfor dårlig resultat.
Den første timen med trening får man gratis, så nå er det bare å fyre løs. Som Google selv sier kan treningen ta alt fra 15 minutter til flere timer. Det avhenger av flere faktorer, og blant dem er størrelsen på datasettet. For våre ynkelige 20 bilder tar det knapt fem minutter. Det er så vidt man rekker å hente litt fersk kaffe i koppen før man fortsetter.
Når treningen er ferdig kan vi hive inn tilfeldige bilder av pizza, og se om systemet selv klarer å sette riktig kategori på bildene. Da jeg fortalte systemet hva som beskrev en god pizza valgte jeg utelukkende pizzaer med ananas. Her er det uenigheter i verden om hvor rett det valget er, men alt vi har gjort så langt er såpass lett at om du skulle være uenig, så kan du slenge opp en egen modell på under en time. Men la oss sette i gang.
Først, såklart, må vi jo prøve å se om modellen klarer å gjenkjenne den syrlige sødmen av ananas på pizza for det den er, nemlig en god pizza.

Suksess! Tallet til høyre forteller oss hvor sikker modellen er på at den har rett. Tallet “1” er maks poengsum – og her er jeg helt enig med resultatet.
La oss prøve en pizza uten ananas.
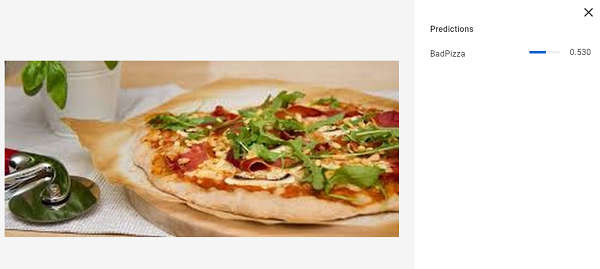
Her gir også modellen “korrekt” resultat, men den er mye mindre sikker på valget. Trolig kan det komme av lyse toner i osten, som kan minne om ananas.
La oss se hva modellen sier hvis vi gir den noe helt annet enn det den har trent på.

Kebab er noe modellen aldri har sett før, så her har den lite data å forholde seg til. Men den gjør så godt den kan, og velger å kalle dette for en “GoodPizza”. Kanskje maisen har noe med det å gjøre.
Men hva hvis vi prøver dette?

Aha! Her ser vi at modellen er rimelig sikker på at dette er en god pizza, men vi kan jo ikke si oss enige selv.
Det som antakeligvis har skjedd, er at modellen har fint lite kunnskap om hva som er, eller ikke er, en pizza. Det den derimot vet, er at alle bildene av “GoodPizza” inneholder ananas. Ananas i seg selv er altså den største og mest tydelige ulikheten mellom de to kategoriene vi har tildelt modellen, og dette har den tydeligvis plukket opp. Kult!
Så hva sitter vi egentlig igjen med etter alt det her, sånn rent utenom en modell som kan gjenkjenne ananas? Google har reklamert med at AutoML skal være fryktelig lett å bruke, og at det skal kreve veldig lite maskinlæringskunnskap fra brukeren. Etter å ha gått gjennom stegene for å sette opp og trene denne modellen må jeg si at de har fått det til. Jeg har ikke peiling på nøyaktig hvilke algoritmer som ligger i bakgrunnen, og ikke trenger jeg å vite det heller. Det eneste jeg trengte var bittelitt kunnskap om hvordan man skal ta i bruk Google Cloud-ressurser. Resten var kan gjøres via normal mappestruktur på en virtuell hardisk (“Cloud Bucket”).
Det blir veldig kult å se hva som kommer ut av AutoML videre. Det er fortsatt to tilgjengelige moduler jeg ikke har testet, nemlig AutoML Translation og AutoML Natural Language. Det blir spennende å se hva de kan brukes til, og om de er like enkle å ta i bruk som Vision.
Er du også opptatt av ny og spennende teknologi?


