
«Data, den nye oljen» har blitt en kjent frase de siste årene, og markedet har følgelig kastet seg inn i en digital transformasjon og modernisering for å møte kundenes forventning til leveranse i høyt tempo, med høy kvalitet. Likevel, til tross for at tidsskrifter som Forbes og The Economist stiller seg bak påstanden med store overskrifter, så kreves det mer enn kun data for å skape verdi.
Det er dette som er hovedbudskapet i Qlik sin rapport over 10 data- og BI-trender for 2020: «Analyse er ikke nok». Deres prediksjon er at vi i 2020 vil se en trend hvor teknologi og prosesser går mot en mer holistisk ende-til-ende løsning for data, noe de hevder vil revolusjonere dagens praksis.
Spesielt spennende er det når Gartner i tillegg spår at for hver nyansatte ekspert i en IT-avdeling vil det ansettes tre data- og analyseeksperter i firmaet. Da kan vi ikke bli annet enn nysgjerrige på om spesielt én av Qlik sine påstander kommer til å spille en særdeles viktig rolle i veien fra data til verdiskapning, nemlig:
DataOps pluss self-service er det nye «smidige».
DataOps – DevOps for data?
DataOps har blitt et av de heteste nyordene innen data og analyse, og begrepet dukket for første gang opp på Gartners såkalte hype-cycle for data management i 2018. Navnet gir for mange en assosiasjon til den kjente metodikken DevOps, noe som peker de fleste på god vei i riktig retning.
DataOps er i likhet med DevOps en automatisert, prosessorientert metodikk som bygger på hva DevOps gjorde best, nemlig å innføre en iterativ arbeidsprosess for å kutte ned ende-til-ende tiden og forbedre kvaliteten på dataforvaltningen. Dette innebærer både å levere inkrementelle forbedringer løpende innad i teamets prosjekter, men også å knytte tettere bånd med de andre avdelingene og samarbeide på tvers. Det for å informere om hvilke data som finnes, hvilke analyser som kan muliggjøres og hvordan dette kan være til fordel for avdelingene på tvers og selskapet som helhet.
Det er på dette punktet at DataOps skiller seg litt fra DevOps. Denne metodikken krever en kulturendring i hele selskapet, ikke bare på en avdeling eller i et team. Veien til mål vil derfor i stor grad avhenge av selskapets historie. Store selskap sitter på tung historikk, ansatte er ofte separert i siloer basert på teknologi, og kommunikasjonen stopper gjerne ved trappen til neste etasje.
Hos startups er veien mot en samlet visjon og strategi ofte kortere, historikken er mindre tyngende eller ikke eksisterende og kulturen må ikke i like stor grad endres. De må likevel være bevisste. Hver enkelt har sin historikk og nå må den nye gruppen stake ut sin felles retning.
Les mer: Hvordan skape en datakultur?
Så mens DevOps ble laget for å tjene utviklerne (illustrert ved det kjente uendelighetstegnet) er fokusgruppen til DataOps bredere enn kun analytikerne. Kanskje er det til og med analytikerne som må endre kulturen mest. Enkelte må gå fra å være eksperten på sin algoritme til å bli eksperten på hvilken innsikt algoritmen kan gi og hvor dette vil skape verdi.
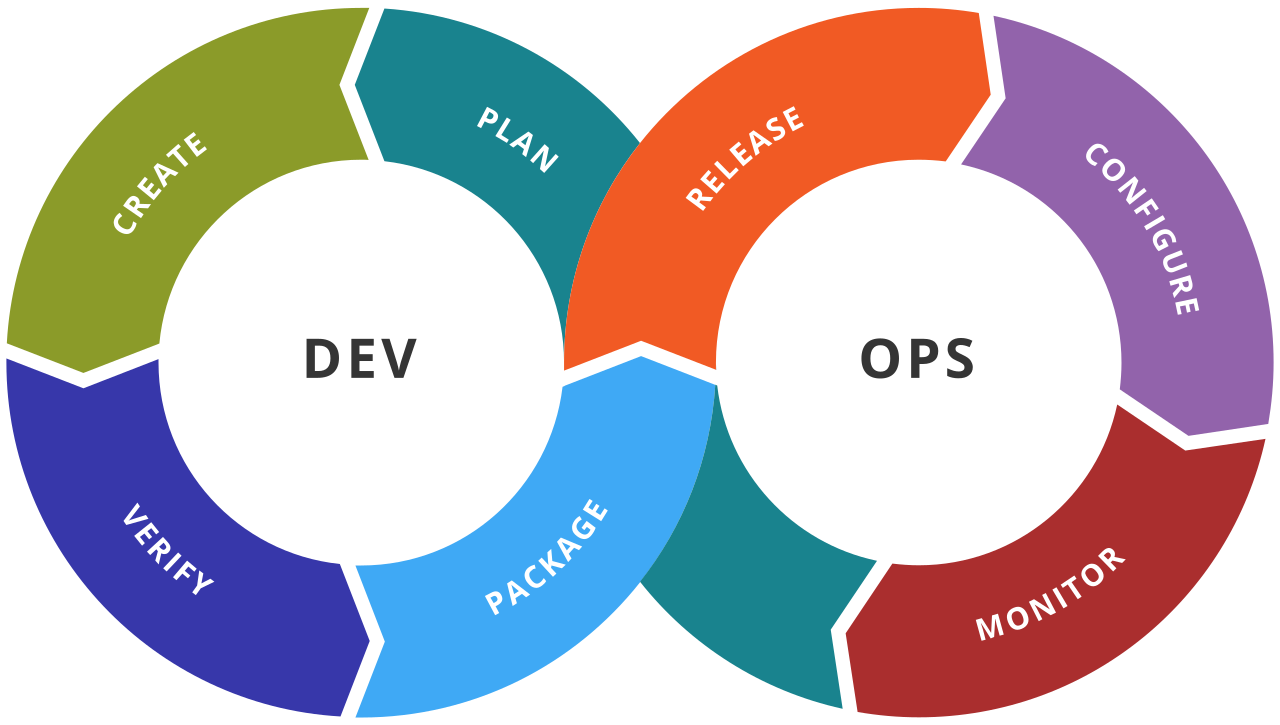
Les mer om data literacy her.
DataOps handler altså mye om at vi må snakke samme språk og arbeide sammen i tverrfaglige team for å bryte ned siloene og fordele kunnskapen ut i hele selskapet, uavhengig av selskapets størrelse. Endringen blir bare tilsvarende skalert. Når de andre avdelingene kjenner datagrunnlaget, kan de også bistå der de er best, nemlig å se verdien av dataen i deres verden.
Vil du lese om flere av årets trender? Sjekk ut BI Trend Monior 2020 fra Barc:
DataOps for analytikeren
Ved å implementere metodikken DataOps i en bedrift legger man altså til rette for at tverrfaglige team kan fokusere på inkrementelle løsninger og automatiserte prosesser. Det blir en raskere dialog med potensielt en større forståelse for behov og gjensidig empati for prioriteringer.
All effektivisering frigjør tid til å automatisere prosesser for innhenting, massering og vasking av data, noe som igjen frigjør analytikernes tid. Og med Qlik og Gartner sine prediksjoner i bakhodet om at antallet analytikere vil øke kraftig de neste årene, så er denne frigjøringen av tid særdeles viktig!
Forbes rapporterer at en analytiker bruker ca. 80 % av tiden sin på å forberede data og 76 % av de spurte mente at dette var det minst artige med deres jobb.
Hva er så det neste steget vi kan ta for å frigjøre mer tid hos analytikeren slik at de får drive med sine interesser og skape mest mulig verdi ut av dataene, ikke bare samle de?
Self-service BI
Nå er i grunnen alt klart for å levere inkrementelt også på rapporteringsfronten og hva hadde vel ikke vært bedre enn om brukerne selv kunne grave og leke med dataene?
DevOps har bevist at om veien fra ide til løsning og fra oppdaget feil til korreksjon er minimal, skapes gode brukeropplevelser, engasjement og et ønske om mer.
Slå sammen DataOps og self-service BI og vi er godt på vei!
Analyseteamet kjenner dataen godt og kan bygge gode rapporterings- og analyseløsninger i BI-verktøy som Qlik, PowerBI og Tableau. Disse verktøyene er skreddersydde for at brukeren selv kan sette sammen rapporter på kort varsel i det behovet oppstår!
Self-service gir nettopp den nødvendige fleksibiliteten som kreves i en presset arbeidshverdag hvor svaret trengs akkurat her og nå. Det reduserer time-to-market, og i samarbeid med analytikerne går ikke dette på bekostning av hverken kvalitet eller effektivitet for kritiske bruksområder. Etter tid vil standarder bygges opp og rapporter kan gjenbrukes for å bidra til økt selvstendighet hos brukeren.
Så er DataOps pluss self-service det nye smidige?
En illustrasjon hentet fra Medium oppsummerer det hele godt ved å vise hvordan DataOps bringer sammen tre innovasjonssykluser på tvers av kjernegrupper i organisasjonen: sentraliserte produktteam, sentraliserte utviklings/analyse/forskning/forvalningsgrupper og til slutt gruppen av brukere som anvender self-service verktøy.
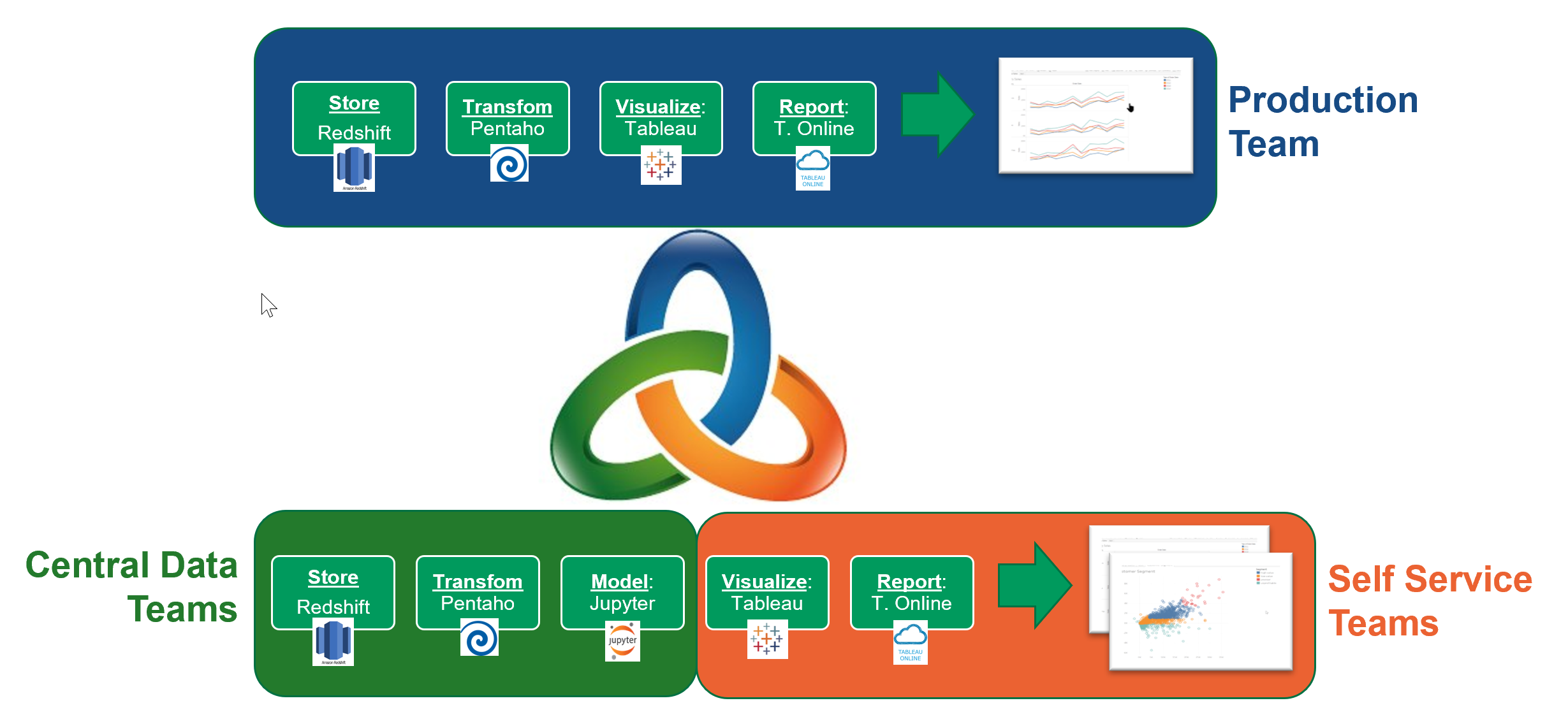
Oppsummert; DataOps pluss self-service utnytter det beste fra begge verdener, nemlig DevOps og BI, og kombinerer dette til en smidig arbeidshverdag. Hvor bedriften tar i bruk avdelinger der de er best, og samarbeider for å skape den gode kulturen som vil gi dem innovasjon og utvikling i tråd med deres strategi.
For det er sjeldent at det er teknologien som bremser for de store endringene, det er menneskene og den kulturen vi etablerer sammen helhetlig som et selskap som setter kursen. Klarer du som leder å så de samme frøene både hos utviklerne, data scientistene og markedsavdelingen slik at disse kan snakke samme språk rundt kaffemaskinen, samarbeide på tvers av teknologistacken og oppnå felles strategi og verdi for selskapet?
Uansett om svaret er ja eller nei per nå, så må vi da kunne tørre å si oss enige i at DataOps pluss self-service er en smidig brikke i veien mot verdiskapning.
Nysgjerrig på rapporterings- og analyseverktøy? Vi holder flere gratis introduksjonskurs i blant annet Qlik, PowerBI og Tableau.


