
Parallelt med all blesten har vi gradvis sett at løsninger som benytter maskinlæring er tatt i bruk, løsninger som daglig genererer store gevinster. Et eksempel er hvordan maskinlæring har sørget for automatisering og bedre kundebehandling i Visma sitt kundesenter.
Det er sagt og skrevet mye om hva maskinlæring og kunstig intelligens er, og hvilke løsninger vi kan lage, så det skal ikke repeteres her. Denne artikkelen fokuserer i stedet på å gi en overordnet framgangsmåte for implementering av maskinlæring.’
Hvordan gå frem når du vil implementere maskinlæring i dine løsninger?
Utgangspunktet er at du har identifisert et område, eller en problemtype, som er egnet for maskinlæring. Dette er ofte problemtyper som ikke lar seg løse med tradisjonell regelbasert deterministisk programmering. Eksempler på områder som typisk egner seg kan du lese mer om i artikkelen “Kan maskinlæring løse alle problemer?”.
Med utgangspunkt i området du har identifisert er følgende overordnede framgangsmåte en metodisk, prosessorientert tilnærming for å implementere maskinlæring:
1. Kartlegge, analysere og dokumentere arbeidsprosesser og datasett
Første steg i prosessen er å kartlegge og analysere arbeidsprosessen og data innenfor det området du har valgt deg ut. Er arbeidsprosessen og tilgjengelige datasett gode nok for maskinlæring? Disse vurderingene dreier seg om flere faktorer, slik som størrelse på datasett, antallet variabler, og statistiske styrker og sammenhenger i datasettet. Dette er vurderinger som typisk gjøres av en data scientist.
Dersom arbeidsprosessen og tilgjengelige datasett er gode nok kan du gå videre til steg 2 i denne framgangsmåten.
Dersom svaret er nei, det vil si arbeidsprosessen og/eller dataene ikke er gode nok for maskinlæring, må du vurdere følgende:
- Arbeidsprosessen er ikke god nok til å kunne bli automatisert: Når dette er tilfelle må du redesigne arbeidsprosessen slik at automatisering blir mulig. Du må også sikre at IT-systemet genererer data med høy kvalitet. Nødvendige tilpasninger for å få til dette kan for eksempel være at frivillige felter blir gjort om til obligatoriske felter, fritektstfelter blir endret til nedtrekksmenyer, osv.
- Arbeidsprosessen er god nok, men du mangler tilstrekkelig mengde av data: Når dette er tilfelle må du generere en større og mer representativ datamengde. Det gjør du ved å kjøre arbeidsprosessen tilstrekkelig mange ganger. Et alternativ er å generere syntetiske data, det vil si å etablere et syntetisk data vault.
Vil du vite mer om maskinlæring? Bli med på vårt gratis introduksjonskurs til maskinlæring:
2. Sette opp maskinlæringsmodell og velge egnet algoritme
Når både arbeidsprosess og datamengde er vurdert som gode nok er neste steg i framgangsmåten å velge en passende algoritme. Det finnes en rekke maskinlæringsalgoritmer å velge mellom. Maskinlæringsbiblioteket Scikit Learn er et eksempel på hvor du finner slike.
Å velge riktig algoritme gjør du ved å vurdere hvilken matematisk modell som passer best for området du skal lage en maskinlæringsløsning for. Eksempler på algoritmer er nevrale nettverk, Bayesian og Deep Learning. Når du har valgt algoritme må du kople algoritmen og arbeidsprosessen, slik at algoritmen kan begynne å jobbe med datasettet ditt.
Et godt tips i arbeidet med å velge riktig algoritme er å prøve ut flere forskjellige algoritmer, for det er på denne måten kan finne ut hvilken algoritme som er best egnet. Når dette er gjort er du klar for neste steg.
3. Trene modellen
Steg tre handler om å trene og konfigurere algoritmen basert på et empirisk datasett. Du skal trene opp maskinlæringsmodellen din basert på historiske data. Treningen innebærer å kjøre et tilstrekkelig antall iterasjoner, typisk noen titusener iterasjoner, slik at algoritmen lærer alle tilfeller, alle «corner cases» og grenseverdier, å kjenne. Ved behov kan du også konfigurere manuelt ved å sette grenseverdier, legge inn vekting av tilfeller, bestemme hva som skjer innenfor og utenfor grenseverdiene.
Det er også mulig å kople på en tilbakemeldingssløyfe i modellen. En slik tilbakemeldingssløyfe er nyttig når det oppstår tilfeller som ikke finnes i de empiriske dataene dine. Maskinlæringsmodellen vil da registrere disse tilfellene, og begynne å lære hva som er riktig håndtering av de nye tilfellene.
Les mer: Guide til analytics, maskinlæring og dataforvaltning
Et viktig element i treningen av modellen er å spare en andel av datasettet ditt til å validere modellen. Når du er ferdig med treningen må du validere om du får riktige resultater basert på data som modellen ikke har sett før. Dersom du bruker hele datasettet i treningen har du ingen data til å validere med. En god tommelfingerregel er derfor å holde igjen ca 20% av datasettet ditt validering.
Figur 1 viser en skjematisk framstilling av en maskinlæringsmodell.
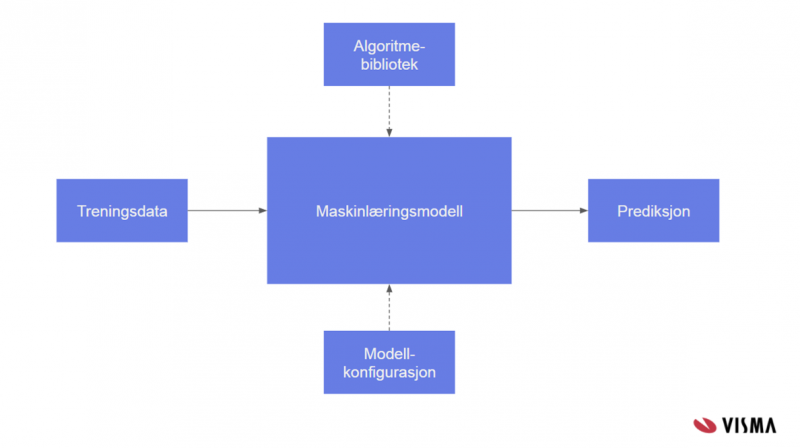
4. Installere i produksjon
Når treningen av algoritmen er ferdig er du klar til å installere løsningen for maskinlæring i produksjonsmiljøet ditt. Du integrerer med de nødvendige IT-systemene slik at virkelige produksjonsdata kan begynne å strømme gjennom løsningen. Du er endelig klar til å begynne å høste gevinstene av investeringen din.
5. Vedlikehold og videreutvikling
Etter at løsningen for maskinlæring er satt i produksjon er det viktig å vedlikeholde og videreutvikle løsningen. Selv om du gjorde en grundig trening av modellen din kan det oppstå endringer i omgivelsene du må håndtere, og det kan også være at du ønsker å videreutvikle modellen din. Dersom du for eksempel har laget en løsning som håndterer kategorisering og ruting av saker, kan en mulig utvidelse være at løsningen for maskinlæring også skal begynne å løse sakene.
Vi er nå ved veis ende i denne overordnede framgangsmåten for å implementere en løsning for maskinlæring. Lykke til med dine maskinlæringsprosjekter.


