
Målet er å lage et system som automatisk genererer syntetiske data. Konseptet The Synthetic Data Vault (SDV) baserer seg på bruk av maskinlæring og statistikk for å trene modeller som, i motsetning til anonymisering/maskering, genererer datasett med statistiske egenskaper som blir identiske med de originale produksjonsdataene.
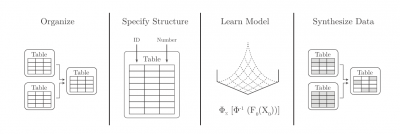
The SDV workflow (Patki, 2016)
The SDV workflow (Patki, 2016) beskriver en fire stegs prosess for å etablere SDV, først organiseres produksjonsdata fra alle tabellene i separate filer, deretter spesifiserer man datatyper og relasjoner, trener opp modellen og til slutt genereres det opp syntetiske data til et SDV.
Datakvaliteten på produksjonsdataene er helt avgjørende for at konseptet basert på SDV blir vellykket. Om datakvaliteten er god nok oppdages ofte ikke før læring av modellen er prøvd ut den første gangen. I mange tilfeller må det tas et eller flere steg tilbake for å se på hvordan produksjonsdataene blir skapt. Dårlig datakvalitet er som regel knyttet til fagsystemer og arbeidsprosessene hvor data blir til, så disse må ofte utbedres for å heve kvaliteten.
Et praktisk tips er derfor å starte raskt med å trene modellen, da vil man oppdage svakheter tidlig og nødvendige utbedringer kan gjøres uten for mye bortkastet tid, så “prøv og feil” er en god arbeidsmetode for å komme i gang med SDV basert på maskinlæring.
Når SDV er etablert med tilfredsstillende kvalitet, må det forvaltes og vedlikeholdes, ved feks. endringer i fagsystemene eller prosessene som skaper produksjonsdata, må modellen trenes på nytt og et nytt SDV genereres.
Bruksområdene for syntetiske produksjonsdata basert på anonymisering/maskering av produksjonsdata er begrenset, disse dataene blir som regel laget for et spesielt formål og er lite anvendelig utenfor dette området. Syntetiske data basert på SDV har et langt større bruksområde og kan i praksis sidestilles med reelle produksjonsdata, eksempler er:
- Trening av maskinlæringssystemer generelt
- Effektiv og repeterbar generering av testdata med kvalitet som på produksjonsdata
- Skalerbare datasett for feks. ytelsestesting
- GDPR- relaterte krav til håndtering av personrelatert informasjon
- Isolere produksjonsdata fra utviklingsprosesser og miljøer slik at færrest mulig får tilgang til produksjonsdata
- Data Science/Data mining/Data Visualization oppgaver kan utføres mot syntetiske data
- Trening av maskinlæringssystemer beregnet for avdekking av misbruk (Fraud Detection).


