
Man har i praksis disse valgene:
- Tolke eksisterende formål med innsamlingen av persondata på en slik måte at det også gis anledning til å bruke produksjonsdata til utvikling, test og forvaltning av IT-systemene.
- Syntetisere produksjonsdata ved hjelp av maskinlæring slik at de blir et fullgodt speilbilde av produksjonsdataene, men at personopplysningene er fullt ut anonymiserte og ikke på noen måte mulig å gjenskape.
Noen virksomheter tar sjansen på at eksisterende formål er godt nok også etter GDPR med de store konsekvensene dette kan få.
Les mer: GDPR-vennlige data til test og analyseformål
Hvordan sikre at personopplysningene er anonyme?
Enkel anonymisering eller maskering av data er ikke godt nok fordi det da er stor sannsynlighet for at personopplysningene på ett eller annet vis kan gjenskapes.
Løsning:
- Anonymisere dataene og gjøre dem syntetiske ved hjelp av maskinlæring. Da er det fritt frem å bruke dataene til utvikling og test av IT-systemer samt avanserte analyser og visualiseringer. Bruken faller da utenfor det GDPR regulerer.
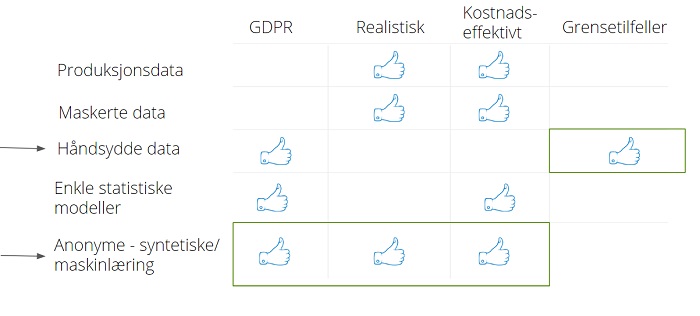
- Får å få fullgode testdata bør man i tillegg komplettere dataene med grensetilfellene (“cornercases”) som ikke finnes i produksjonsdataene i utgangspunktet.
- Det syntetiske datasettet bør også gjøres dynamisk, det vil si ta høyde for de daglige endringene som skjer i produksjonsdataene. Disse endringene må også syntetiseres.
Oppsummert får man på denne måten et komplett datasett som tilfredsstiller GDPR, er realistisk (de statistiske egenskapene er ivaretatt), genereres kostnadseffektivt, gjenspeiler daglige endringer og inneholder alle ønskelige grensetilfeller.
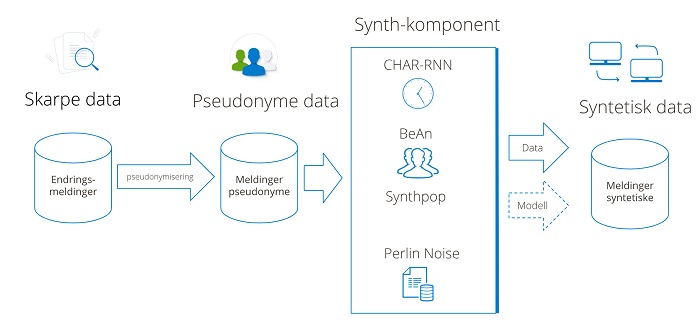
Figuren over viser Visma Consulting sitt konsept for syntetisering av produksjonsdata (skarpe data) via pseudonymisering og maskinlæring. For eksempel kan vi syntetisere meldinger om nye fødsler fra folkeregisteret. Et sett skarpe fødselsmeldinger trekkes ut fra kildesystemet og blir deretter pseudonymisert. Dette betyr at alle direkte identifiserbare attributter, som fødselsnummer og navn, blir erstattet med noe annet.
Deretter kjører vi det pseudonyme datasettet inn i en synth-komponent. Dette kan i prinsippet være hva som helst, men denne komponenten må kunne lære seg en statistisk representasjon av det pseudonyme datasettet. Synth-komponenten gir enten fra seg den maskinlærte modellen som vi senere kan hente ut syntetiske data fra, eller den gir fra seg de syntetiske dataene direkte.
For at de syntetiske, dynamiske dataene skal holde en kontinuerlig høy kvalitet må de forvaltes som om de var produksjonsdata.
Vil du lære mer om hvordan du kan benytte maskinlæring i dine business intelligence og analytics prosjekter?


