Artificial Intelligence
Maskinlæring, deep learning, reinforcement learning. Buzz eller business? Hvis du spør oss, finnes det fordeler med AI for alle – i alle bransjer.
/Ung%20dame%20sitter%20og%20jobber%20konsentrert%20p%C3%A5%20en%20PC.jpg?width=1280&height=1280&name=Ung%20dame%20sitter%20og%20jobber%20konsentrert%20p%C3%A5%20en%20PC.jpg)

Kampanjetilbud: 3 timer workshop med twoday AI Agent
Vil du ta din virksomhets kundeservice og databehandling til et helt nytt nivå? Nå har du sjansen til å gjøre det med twoday AI Agent! Og det beste av alt? Vi har nå en kampanje hvor du får 3 timer med workshop for kun 4000 kroner!
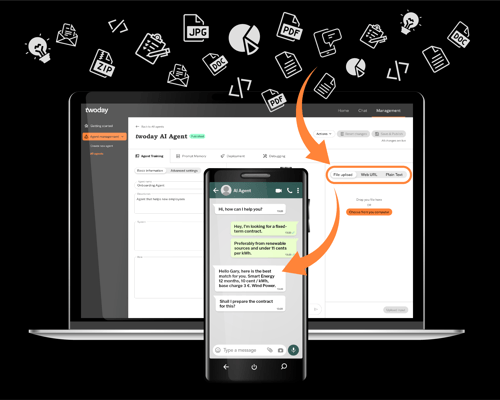
twoday AI Agent tar virksomhetens informasjonsbehandling til et nytt nivå
Si velkommen til en ny superkraft i din virksomhet! twoday AI Agent er en banebrytende AI-applikasjon, som ved hjelp av kraften i GPTs språkmodell forbedrer og effektiviserer driften, i tillegg til å automatisere dine tjenesteprosesser.
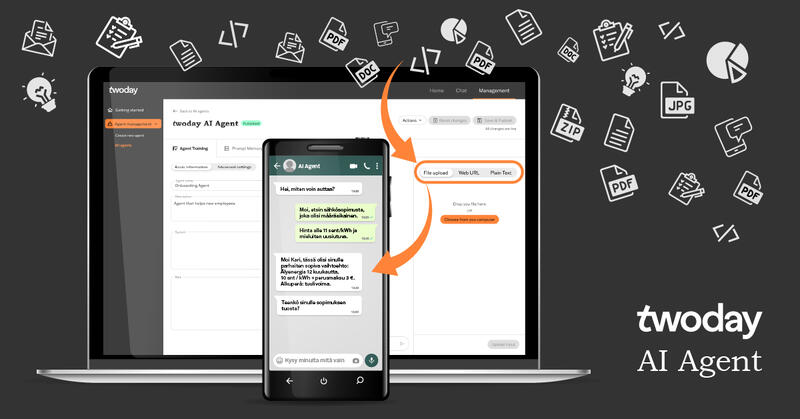
Artificial Intelligence i praksis

Avansert analyse
Maskinlæring er godt egnet til analytiske formål, og kan brukes til å utvikle en rekke modeller som hadde vært vanskelig eller umulig å utarbeide med tradisjonelle teknikker: Prediksjoner og regresjon, Clustering, mønstergjenkjenning og risiko-identifisering, Årsaks-virkningsanalyser og Statistisk analyse.

Avansert automatisering
Maskinlæring gir mulighet for å lage modeller og funksjoner som lærer og tilpasser seg kontinuerlig fra data som flyter i systemet. Dette kan være klassifiseringer, mappinger, fordelinger med mer.

Tolkning av naturlig språk
Natural Language Processing (NLP) er tolkning av menneskelig skrift eller tale. Det er en viktig del av å bygge smarte maskiner fordi de fleste applikasjoner vil interagere med mennesker på en eller annen måte.

Bots
Boter kan stå for et bredt utvalg av arbeidsoppgaver, både maskin til maskin og gjennom interaksjon med mennesker. Chatbots er en av de vanligste implementasjonen.

Automatisert kundesenter
Innkommende henvendelser til kundesenteret kan ved hjelp av maskinlæring analyseres og fordeles automatisk til riktig behandler. Behandler kan enten være en saksbehandler eller for enklere henvendelsestyper kan behandlingen være helautomatisert.

Andre kognitive teknologier
Vi forsker på og utvikler løsninger med en rekke andre kognitive teknologier. Dette er klassiske teknologier som bildegjenkjenning, men også Virtual Reality (VR), Augmented Reality (AR) og fysiske roboter.
Gratis webinar:
AI for bedrifter – klar til bruk nå!
I dette webinaret dykker vi ned i årets største snakkis, nemlig artificial intelligence (AI) og hvordan du kan bruke AI i praksis. Vi lover også en demo av den nye AI-applikasjonen vi har utviklet som kombinerer effektiviteten fra ChatGPT med sikkerhet.



_felles/En%20gruppe%20mennesker%20st%C3%A5r%20sammen%20ved%20et%20langt%20bord%20og%20prater.jpg?width=500&height=500&name=En%20gruppe%20mennesker%20st%C3%A5r%20sammen%20ved%20et%20langt%20bord%20og%20prater.jpg)
/Ansatte%20og%20foredragsholdere/Trine_800x600%20(1).jpg?width=800&height=800&name=Trine_800x600%20(1).jpg)