
Når Col. James Burton (Cary Elwes) nekter å godkjenne The Bradley Fighting Vehicle for produksjon grunnet manglende testdekning i TV-filmen “The Pentagon Wars” (1998) får han til svar av General Patridge (Kelsey Grammer) “We’ll do what we’ve always done! We’ll fix it in the field!”.
Dette var lenge mantra også i IT verden. Det hørtes nok forførende ut når Facebook delte sin “move fast and break things” filosofi. Det viste seg å være en ganske skakkjørt tankegang som sjelden var til fordel for sluttbrukerne. Heldigvis har man kommet til fornuft og man ønsker i dag å oppdage feil så tidlig som mulig. Man fant ut at det var billigst.
Det vi ønsker er en smidig prosess som ivaretar sikkerhet og personvern, leverer stabilitet og forutsigbarhet, og samtidig ikke føles som en flaskehals. ITIL tilnærming er det ingen som vil tilbake til (men mange henger igjen her enda).
Telekommunikasjonsbransjen skjønte at top-down strategien ikke var det mest gunstige, og som en reaksjon vokste det frem en bottom-up stil på 90 tallet som vi i dag kjenner som DevOps. Målet var fleksibilitet. At teamet kunne være så dynamisk at de kunne endre seg raskt. At de skulle kunne ta stilling til uforutsette problemstillinger og endringer uten å måtte gå gjennom rigide rammeverk og beslutningsprosesser.
På 2010 tallet og utover begynte begrepet å sirkulere i overflaten av IT verden. Lean og Scrum og andre smidige, iterative, prosesser var allerede godt etablert. Med DevOps kom ønsker om enda mer smidighet ved hjelp av automatisering og en liten restrukturering av tekniske team. Utviklere og driftere skulle sitte mye tettere sammen, og man skulle ikke lenger bare utvikle applikasjoner men også samlebåndene med roboter som lagde applikasjonene. Mer automatisering, mer gjenbruk og en tydeligere separasjon mellom forretningsfunksjonalitet og støttetjenester. Nedenfor er en liste med konsepter som bør være en del av din automatiserte bygg og deploy pipeline.
En bygg- og deploy pipeline består av en samling automatiserte og manuelle mekanismer. Det er nesten litt feil å kalle de som forvalter slike løsninger for driftere lenger, ettersom disse pipelinene overhodet ikke er statiske objekter. De skal kodes og scriptes og forvaltes nesten på lik linje som applikasjonene som håndterer forretningslogikken din. Målet med slike pipelines er å kunne bygge, teste og deployere løsninger raskere og tryggere, samtidig som de skal levere sikkerhetskontroller og metrikker. Moderne driftspersonell må belage seg på å kode mye mer fremover nå som Infrastructure as Code er i mote.
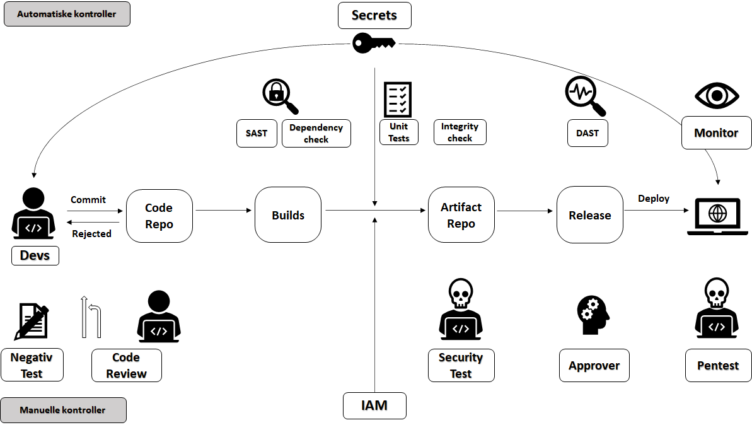
Automatiske mekanismer
Vi ønsker å automatisere alt vi kan. Automatiserte prosesser forhindrer menneskelige slurvefeil, de kan raskt repeteres, og er målbare. Automatiserte prosesser kan også dupliseres og integreres i andre pipelines slik at man slipper å finne opp hjulet på nytt hver gang. Det spiller ingen rolle om du jobber med moderne orkestrering av kontainere som Kubernetes full av applikasjoner med mikrotjeneste-arkitektur, eller om du sitter med mer tradisjonelle miljøer som virtuelle maskiner og multinivå design. De fleste produkter i dag har et API du kan integrere deg mot og automatisere, og har det ikke det som bruker du sannsynligvis et elendig verktøy.
Nedenfor følger nå en del mekanismer man kan integrere og automatisere i våre pipelines.
1. Gated commits / Gated check-ins
Utviklere skriver kode, lager enhetstester som kjøres lokalt og deretter pusher de arbeidet til kildekode versjoneringssystemet (som i 99% av tilfellene vil være Git). Koden trigger deretter et automatisert bygg som verifiserer at den ikke bryter med eksisterende kode. Noen ganger går det greit og koden integreres i branchen, mens andre ganger smeller det og alle på teamet lurer på hva som er årsaken til at release-branchen nå ikke er grønn. For å mitigere dette startet man med gated-commits, eller gated check-ins. Målet var å hindre koden å nå release-branchen hvis den ikke var av god nok kvalitet. Man fikk heller en kopi av release-branch som man testet sin nye kode på. Hvis tester og bygg går bra så får du lov til å integrere koden din. Hvis ikke er det tilbake til tegnebordet.
Hvordan dette teknisk fungerer er litt opp til hvilken tech-stack du kjører på, men de må kunne ha parallelle commit funksjoner, må kjøres på bygg-server, og bør være enkel og rask å bruke. Gated Commits / Gated Check-ins hindrer ikke elendig kodekvalitet, men kan hindre korrumpering av release-branches og brukne bygg.
Guide: Syntetiske testdata som en løsning for personvern: Hva, hvordan og hvorfor
2. Secrets management
Løsningene du lager i dag har alltid en eller flere hemmeligheter som de må beskytte. Hemmeligheter er f.eks:
- Passord
- API nøkler
- SSH nøkler
- Sertifikater
- Krypteringsnøkler
- Tokens
Man bør definere i pipelinen hva som er hemmeligheter slik at man kan ha på plass sjekker som hindrer utviklere å sjekke inn kode hvor det ligger et hardkodet passord, API nøkkel e.l.. Jo mer vi automatiserer og jo flere verktøy vi tar i bruk jo flere hemmeligheter trenger vi også å styre. Det er derfor nødvendig med en todeling til å hjelpe oss med å levere på denne. Vi trenger å kunne oppdage når hemmeligheter rører på seg og popper opp der de ikke skal være, og vi trenger et verktøy som kan sikre og kontrollere hemmelighetene når de skal opprettes, formidles, brukes, roteres, og slettes.
I Git kan du legge til konfigurasjoner med Git-Secrets hvor du definerer hemmeligheter og du kan sette det opp slik at dette blir skannet for hver gang noen sjekker inn kode. Så kan man benytte verktøy som f.eks. HashiCorp Vault eller Azure Key Vault for selve håndteringen.
3. SAST
Static Application Security Testing verktøy er verktøy som skanner kildekoden din for kodekvalitet, kodefeil, visse sårbarheter, og kan også sjekke avhengighetene dine (tredjepartskode). Det estimeres at SAST verktøy kan detektere ca 45-50% av kjente sårbarheter. Slike verktøy legges tidlig i pipelinen.
Eksempler på SAST verktøy er SonarQube, AppScan, Coverity, Checkmarx, DeepSource, FindBugs, Fortify, GitLab, Nucleus Core og mange mange flere. Det finnes både gratis open-source verktøy og kommersielle produkter. Noen er språk / teknologi agnostiske, mens andre er spesielt laget for en type teknologi.
Fordelene med SAST er at de enkelt skalerer og hjelper utviklerne med å bli flinkere kodere. De er også gode på å finne kjente sårbarhetsmønstre i kode, samt detektere utdaterte versjoner eller kjente sårbarheter i avhengigheter og avhengighetene til avhengighetene.
Ulempene med SAST er at de kan være klundrete å konfigurere til tider, de har en tendens til å gi for mange falske positiver (noe som kan generere mer støy enn lærdom slik at utviklerne slutter å ta stilling til de genererte rapportene) og det er en rekke sårbarheter SAST ikke vil kunne oppdage grunnet at feilene krever at koden kanskje kjører før de blir synlige.
4. Tredjepartskode
Tredjepartskode er noe alle bruker i dag. Dessverre er det ofte slik at man drar inn et stort bibliotek eller rammeverk mens man egentlig bare bruker et bittelite subset av funksjonaliteten. Når man henter inn ekstern kode har often denne koden også avhengigheter til annen ekstern kode som gjør at kodebasen din vokser fort. All kode du drar inn øker angrepsflaten og dette er ekstra risikabelt hvis man henter inn kode som kanskje ikke lenger forvaltes eller er utdatert. Man må ha på plass rutiner for å hele tiden verifisere at man kjører med siste versjon og man trenger såkalte Dependency Checks som skanner det eksterne for kjente sårbarheter. Dette kan man gjøre med SAST verktøy, eller f.eks. legge til kodesnutter som kjører slike sjekker sammen med avhengighetene dine.
Noen ganger kan du komme opp i situasjoner hvor du benytter noe utdatert, eller enda verre, noe som ikke lenger er forvaltet av de som lagde det (så nå er det du selv som eier og forvalter den). Oppdager man da sårbarheter man ikke kan patche må man komme med alternative tiltak rundt som kan minimere risikoen.
5. Risikodreven testing
Også kjent som Negativ Testing. Dette er enhetstester som tester ting applikasjonen IKKE skal få lov til å gjøre. F.eks. sjekke innsending av data med forskjellige enkodinger eller karaktersett for å se om du kan komme deg forbi input validerings filtre eller sikkerhets-headere. Det er en manuell jobb å skrive de første gangen, men er man en flittig person så strukturere man dette arbeidet slik at det blir gjenbrukbart på flere prosjekter. På sikt vil man ha en fin test-suite skreddersydd for virksomhetens applikasjonsportefølje. Disse negative testene kjøres ved hvert bygg på lik linje som alle andre enhetstester.
6. Integritetsstyring
De fleste bygg systemer man benytter i dag genererer en checksum / hash av modulene man legger på artefakt repoet i pipeline. Det lønner seg å automatisere integritetssjekking på modulene når de hentes ned av utviklere eller når deploysystemet skal rulle noe ut til et miljø. Det er en veldig populær angrepsvektor å infisere “ferdige” moduler. Du ønsker også å kunne verifisere forfatter og integritet på kode du henter ned fra internett. All kode du henter i fra en tillitssone til en annen bør skannes for skadevare og verifiseres at den er lagd av noen du stoler på og at den ikke er manipulert.
7. DAST
Dynamic Application Security Testing er verktøy som tester applikasjonen når den kjører. Det sammenlignes ofte med en Blackbox test fra en pentester. DAST verktøy har ikke tilgang til løsningens kildekode, og fokuserer på å avdekke sårbarheter i applikasjonslogikken når den kjører. Meoden til en DAST er å faktisk utføre forskjellige angrep mot løsningen for å se hvordan den håndterer de. DAST løsninger er oftest teknologi- og språk-uavhengige.
Det finnes en del forskjellige produkter på det kommersielle markedet og noen få open-source produkter. Kanskje de mest kjente kommersielle produktene er Netsparker og Burp Enterprise, mens på gratis open-source siden er nok OWASP Zap, Arachni, og Purpleteam de mest kjente.
8. Monitorering
Den eneste måten å vite om det vi gjør er godt nok er å monitorere (overvåke) det. Vi ønsker å avdekke:
- Om de implementerte sikkerhetskontrollene fungerer som forventet
- Bruker vi for mye eller for lite penger på sikkerhetskontrollere
- Verifisere at utviklings- og forvaltningsprosjektene følger virksomhetens krav
- Ressursbruk
- Nettverk, og merkelig trafikk til og fra løsningen
- Flytting av data
- Spørringer og andre applikasjonsspesifikke handlinger
- Tilgangsstyring (feilede innlogginger, aktive koblinger og tidligere innlogginger)
Det er flere forskjellige måter å monitorere på. Du kan parse, presentere og reagere på logger fra nettverk og systemer. Du kan deploye forskjellige agenter rundt om i nettverket og løsningene. Du kan ha reaktiv og proaktive monitorering. At systemet prøver å selv-korrigere seg når det oppdages avvik eller setter systemer i karantene. Flere systemer i dag leveres med såkalt AI kapabiliteter. Her er det mye som skjer om dagen, og det viktigste er at du bruker noe som gir deg verdi, og ikke bare det som ser mest fancy og fint ut.
Manuelle mekanismer
Det er oppgaver du ikke ønsker å ha automatisert eller at de er for komplekse eller for dyre å automatisere. Da må man dra på arbeidshanskene og gjøre jobben manuelt. Her følger noen utvalgte oppgaver du ønsker å se gjort.
1. Self-Security Assessment
Det å få utviklerteamet til å utføre en egenvurdering på sikkerheten i løsningen de jobber på kan ha meget stor verdi. Her får teamet en sjekkliste de må gå gjennom hvor de kartlegger behov, risikoer, arkitektur, sikkerhetskontroller, data, brukere, etc. Dette dokumentet eies av produkteier / tjenesteeier og vil raskt gi en indikasjon på hvor god kontroll teamet har på løsningen de sitter med.
SSA bør være en kombinasjon av tall-score mappet til hvor godt de har dekt punktet. På denne måten kan du bruke metrikkene i scoring av overall sikkerhet i løsningen. Hvis du da også benytter baseline standarder fra dokumenter som OWASP ASVS nivå 0-3 eller NIST SP 800-53 Rev. 4 så kan du score løsningene på hvor godt de imøtekommer det som er satt som krav.
2. Secure code review
Det er veldig vanlig å utvikle med pull-requests hvor en utvikler pusher inn kode, og en annen utvikler må godkjenne koden før den fyker videre for bygging og potensielt migrering med eksisterende kodebase. Dette er veldig viktig for kodekvalitet og kompetansedeling. Mange er veldig flinke til å se på kodekvalitet, kodestil, logikken, optimalisering og ytelse, og om etablerte standarder er fulgt, om test-dekningen er innenfor etc. Men altfor sjelden går man gjennom koden med et rent sikkerhetsfokus.
For at sikkerhet skal ivaretas også på dette manuelle området kan det være hensiktsmessig å benytte trusselmodelleringen. Hva er det funksjonaliteten gjør? Berører den sensitive data? Er brukerkontekst nødvendig? OWASP Code Review Guide kan være et fint utgangspunkt til å komme i gang.
3. Negative enhetstester
Når man begynner et nytt utviklingsprosjekt lønner det seg å alltid utføre en trusselmodellering ved det stadiet hvor man har en skisse over systemarkitekturen. Altså når man vet teknologistacken, de indivudelle modulene, kommunikasjonsprotokollene, tillitssonene og brukere. Trusselmodelleringen blir grunnlaget for de negative enhetstestene og risiko- og sårbarhetsanalysen.
Som nevnt under Risikodrevet testing under Automatiserte kontrollere. Dette er det manuelle stadiet hvor du skriver enhetstester som prøver å avdekke funksjonalitet i applikasjonen du ikke ønsker. Det finnes mange sjekklister med ferdige test-eksempler på sider som f.eks. OWASP Cheat Sheet Series.
4. Penetrasjonstesting (DAST 2)
Dynamic Application Security Testing part 2. Selv om du kan kjøpe eller utvikle dynamiske sikkerhetstestverktøy så klarer de fortsatt ikke å slå en dreven menneskelig pentester. Dette er et felt det jobbes mye med om dagen og maskinlæring vil nok øke de automatiserte mulighetene fremover. Men akkurat i dag så er det lite som slår en erfaren hacker som du slipper løs på systemet ditt for å avdekke brølere.
Dette er et stort felt hvor det er skrevet biblioteker fulle av bøker, så vi skal ikke gå ned i denne materien her. Det som er viktig for å få mest mulig ut av en pentest er at den som bestiller også innehar en del sikkerhetskompetanse.
5. Logging
Siste punktet listet under automatiserte kontroller var monitorering, og for at det skal gi maks effekt trenger vi gode logger. Vi ønsker logger som er enkle å lese for mennesker, enkle å parse av systemer og som ivaretar integriteten i logmeldingene. Man må legge seg på riktig log nivå, benytte sentraliserte log systemer med tilgangsstyring. Logger må også være fri for noen som helst hemmeligheter og annen sensitiv informasjon.
Det store spørsmålet er hva er riktig log nivå og hva skal vi faktisk logge? Svaret her er dessverre det typiske: Det kommer helt an på. Eneste måten å finne frem til riktig log nivå er å begynne å monitorere loggene og endre nivåer og variabler basert på behov. Hva ønsker du å få ut av loggene? Optimalisering og ytelsesdata? Feilede innlogginger og requests med unormal data som input? Hva du er ute etter er opp til løsningen, hvordan den er deployert, hvem som bruker den, etc.